- Open Source CEO by Bill Kerr
- Posts
- The World’s Hottest Industry: Post-Training
The World’s Hottest Industry: Post-Training
A look at the new industry taking the world by storm. ⚡️
Bill Kerr
March 29, 2026

👋 Howdy to the 2,584 new legends who joined since our last edition! You are now part of a 313,311 strong tribe outperforming the competition together.
LATEST POSTS 📚
If you’re new, not yet a subscriber, or just plain missed it, here are some of our recent editions.
🎤 The Speaking Skills Every Leader Needs. An interview with Tristan de Montebello & Michael Gendler, Founders of Ultraspeaking.
👏🏻 The Invisible Layer Separating Good AI From Great AI. An interview with Tyler Phillips, AI Product Lead at Apollo.io.
🚴 Fundraising Fatigue, Hypergrowth & Selling Glovo. An interview with Oscar Pierre, Co-Founder & CEO at Glovo.

PARTNERS 💫
Most AI note-takers just transcribe what was said and send you a summary after the call. Granola is an AI notepad. And that difference matters.
You jot down what matters to you and, in the background, Granola transcribes the meeting.
When the meeting ends, Granola uses your notes to generate clearer summaries, action items, and next steps, all from your point of view.
First impressions matter. Launch a production-ready site in hours with Framer, no dev team required.
Early-stage startups get one year of Framer Pro free. No code, no delays. Scale from MVP with CMS, analytics, and AI localization. Trusted by hundreds of YC-backed founders.
Interested in sponsoring these emails? See our partnership options here.

HOUSEKEEPING 📨
Had a nice little Melbourne newsletter-nerd lunch this week, as part of my decision to try and meet more people across the business and tech ecosystem. As someone who has had crippling anxiety since a traumatic brain injury 12 years ago, it’s pretty hard to live a normal social life. All the things most people think come easily just don’t. But I’ve been building my tolerance for social settings back due to exposure therapy.

Creator crew.
I started with one single catch-up per week, then two, then three, usually with one person, in the morning, or sometimes before lunch, when my anxiety is much easier to navigate. I’ve graduated to a handful of meets per week, sometimes later in the day, with up to three people. I even went to a loud bar the other day for a beer with a mate. Things I’d not have really considered in the last five or six years. Anyway, nothing else to share really, but shoutout to you out there who go through the same struggles. As an old psychologist of mine told me, “It’s better to live life scared than not at all.” Onwards!

BUILDING IN PUBLIC 🔎
The World’s Hottest Industry: Post-Training
Through the 1840s and 50s, more than 300,000 people flooded into California to mine gold. Most didn't strike it rich. The real winners were selling picks, shovels, and jeans (hello, Levi Strauss). This moment in time basically gave rise to the San Francisco we know today. That same San Francisco that, 175 years later, would see a similar flood of capital, human and otherwise, into the city to run headlong into the newest opportunity: artificial intelligence.
To create intelligence at the human level is evocative, above is scary. Orders of magnitude more intelligent—a place most futurists assume we’ll get to sometimes in the next few decades—is downright science fiction. On the one hand, AI could disrupt every industry, displace millions of jobs, and cause social upheaval. On the other hand, it could lead to breakthroughs, from solving sustainability problems to extending the human lifespan to curing cancer.

Trust me, friend.
Whether you think we’re heading towards a future utopia or something much darker, the one thing we can agree on is that there is no stopping this freight train. It’s the modern-day gold rush. The boom of our time. Interestingly, there is one industry, data labelling and post-training, that is growing faster than any other area on earth today. Companies that can help foundation model players, along with their application-layer counterparts, train their models to be smarter, faster, wittier, and more accurate are in short supply. Those that do exist are growing at an incredible pace.
Today, I plan to take a moment to demystify a sector of the industry that functions as the engine room to every AI company on the planet. So buckle up, fuck knuckle, we are going to hyperspace today.
Party at the front
Before diving headfirst into this, I’d like us to acknowledge what the front of house of AI looks like. We’ve all seen it; companies growing at a pace that we’ve never seen before. But it’s not just revenue. They are getting founded and funded like never before. The average SaaS founder is now snickered at in VC circles like an agency business model in years past.
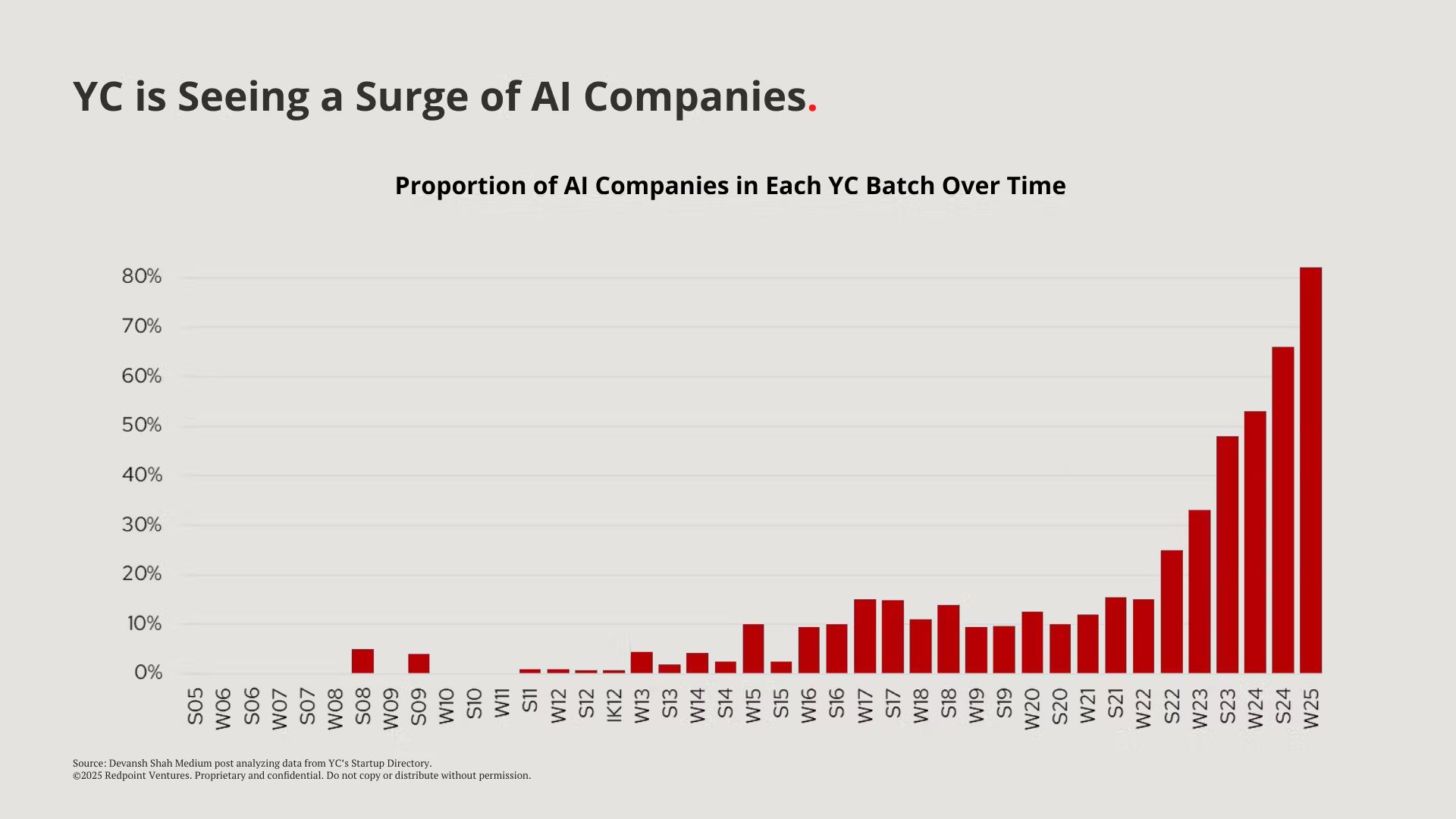 Source: Repoint Ventures. | 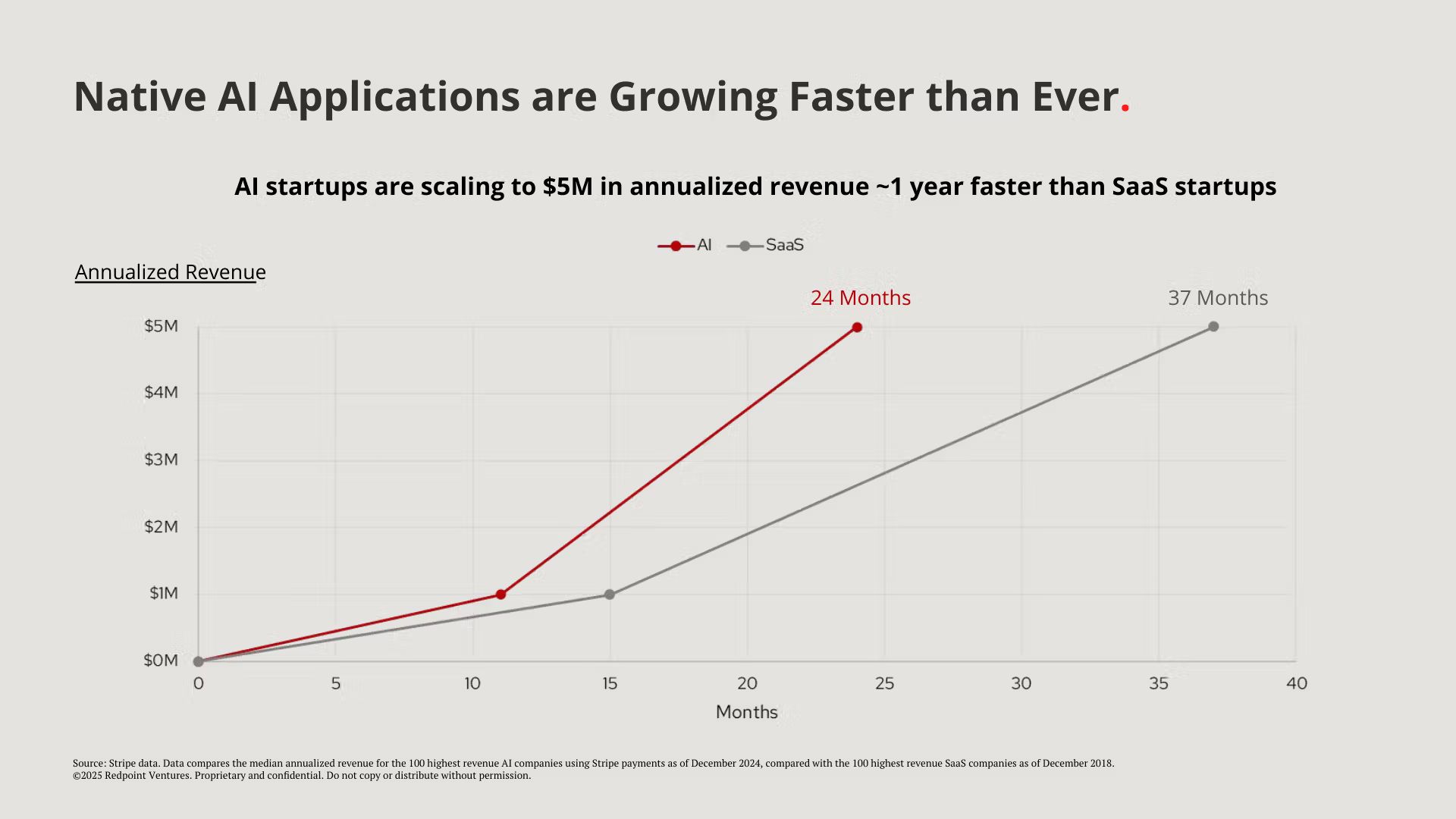 Source: Repoint Ventures. |
Although OpenAI still takes the lion's share of headlines—especially for its ability to raise capital—Anthropic seems to be pulling ahead in the LLM race today. They have grown revenue 10x in the last three straight years, with many projecting they overtake OpenAI sometime between mid-2026 and early 2027.
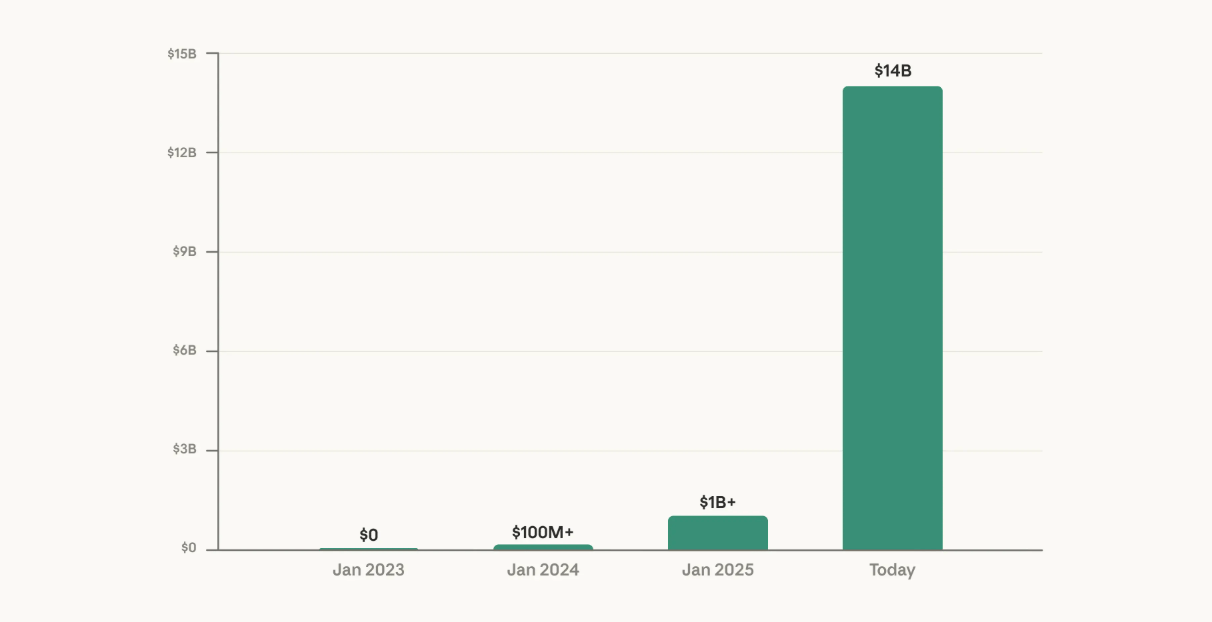 Source: Anthropic. | 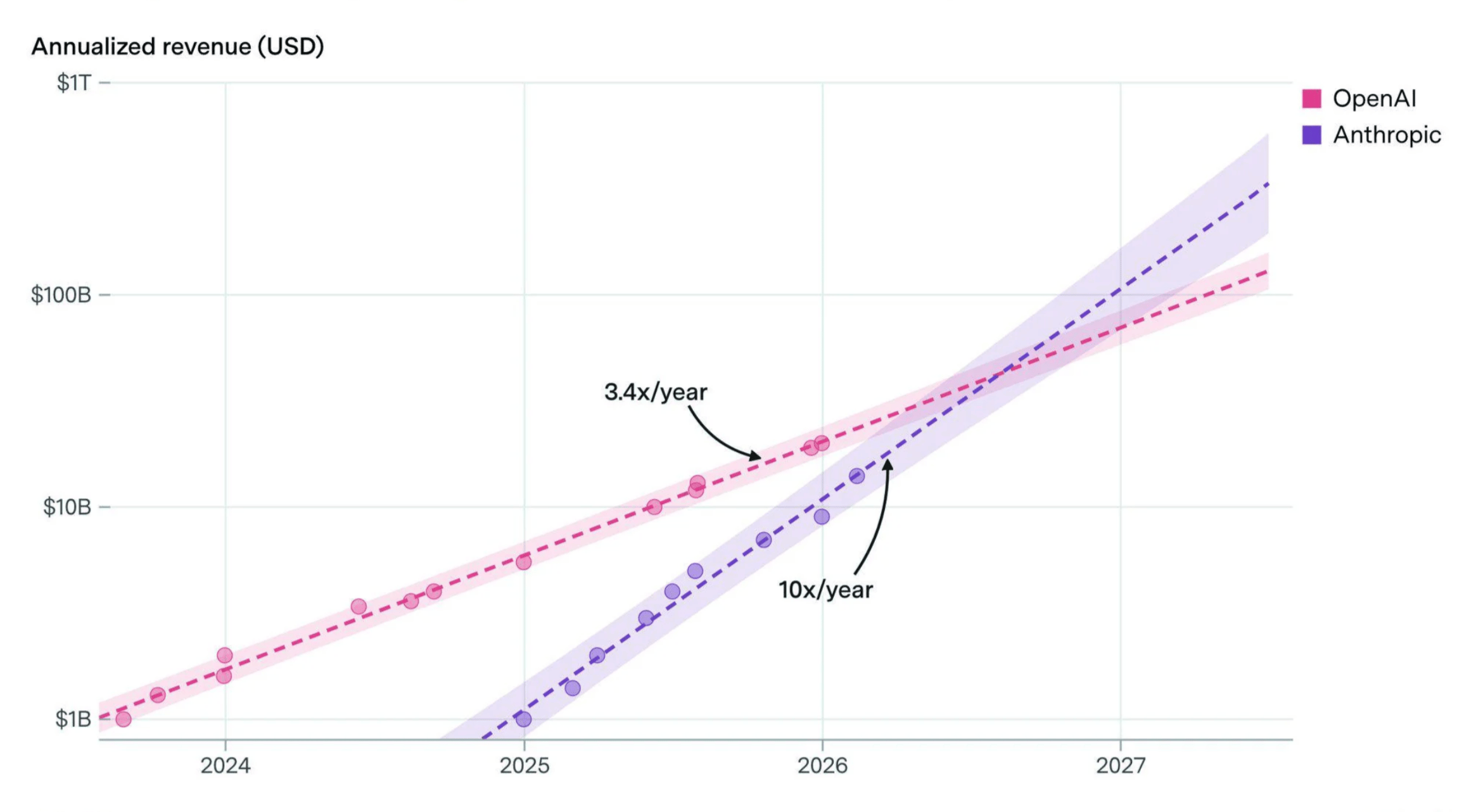 Source: Epoch AI. |
But this piece isn't about the models themselves. It's not about the chatbots, the copilots, or the shiny new AI wrappers getting funded at 100x revenue. This piece is about what happens behind the curtain. The engine room. The bit that makes all of the above actually work.
Because here's the thing nobody wants to talk about at the AI cocktail parties: every single one of these models—ChatGPT, Claude, Gemini, Grok, Llama—needs to be taught. And teaching, as it turns out, is now a multi-billion-dollar industry growing faster than anything else on the planet. Allow me to explain.
How AI actually works (an idiot's guide)
My brother just had his first child. Yep, that means I’m an uncle. Go me! And that child, my nephew Sidney, will feature in the following analogy. You see, there are a few stages that an AI model goes through, very akin to how a human makes their way through the world: failing, learning, growing, adapting. Let’s take a look at these stages for a moment.
Stage #1 - Pre-training (birth through school)
The first stage a model goes through is equivalent to the stage young Sidney is at today. This is where the model is in its heavy-duty information-gathering mode.
For Sidney, it’s learning that bipedalism is awesome, and shitting your pants is only fun for a short while. For our LLM, this is where the model reads the internet. Basically, all of it, good parts and bad. Wikipedia, Reddit, textbooks, news articles, GitHub repos, obscure tweets about whether a hot dog is a sandwich, and whether the deep state cloned your favorite celebrity. Trillions of words, consumed in a matter of weeks by a data center the size of a small town. |  Sidney and his dad. |
And while Sidney is still really at the ‘da-da’ and ‘ma-ma’ stage, so is our LLM. It’s mapping the world, and learning the patterns of language. Soon, Sidney will understand that ‘yum yum’ means food, and that ‘dada’ is often followed by ‘loves me.’ Words will begin to link up. Same thing for the models. Grammar, facts, reasoning, vibes. By the end of this stage, the model is like someone who has read every book in the library but has never had a conversation. Technically knowledgeable. Socially useless.
Stage #2 - Fine-tuning (the internship)
Sidney may have the cerebral horsepower of a turnip at the time of writing, but it will not always be that way. As he goes through school—so long as he doesn’t get expelled multiple times like his rebellious uncle—he will learn all the basics of life. He will read books, learn maths, build and paint things, and when he’s ready, even ask a girl out for the first time. But school is not real life.
*Note: I am including this School of Rock clip for no other reason than it’s awesome. Enjoy.
The same goes for our models. They have learned, but not tried to apply any of their learning to outputs. Now it’s time to take our well-read-but-awkward model and start shaping it. You show it examples of good behaviour: ‘When a human asks X, a good response looks like Y.’ This is where the model starts to feel like a product. It learns to follow instructions, format its answers, and aims to be helpful rather than just technically correct. Think of it as the difference between a university grad who knows everything about accounting and one who can actually file your taxes.
Stage #3 - Post-training / RHLF (the real world)
This is the moment that young Sidney, along with our LLMs, finally grows up. For Sidney, that might mean a quick gap year trip to Trinidad and Tobago (I hear it’s nice), followed by the first steps towards his future career. He'll get his first real job, make mistakes, get feedback from a boss who actually knows what they're doing, and slowly get better. That's exactly what happens to the model. For our LLMs, this is where humans—real, living, breathing humans—sit down and evaluate the model's outputs.
’This answer was better than that one.’
’This response was accurate, but the tone was off.’
’This code compiles but has a subtle bug on line 47 that would crash a production server.’
The model learns from this feedback in a loop: generate → evaluate → improve → repeat. It's called RLHF (Reinforcement Learning from Human Feedback), but what it really means is: humans in the loop, making the machine less stupid, one correction at a time.
The thing nobody wants to say out loud is that models are converging. At the first two stages of our story, all the AI models train on the same data, optimized toward the same benchmarks, and for the most part, the gap between them has closed. The real differentiator now is stage three, expert human feedback applied to actual workflows.
Father of newly-crowned nepo-media-Jesus, David Ellison, and technology mega-chud, Larry Ellison, said the quiet part out loud at a recent Oracle event: models like ChatGPT, Gemini, Grok, and Llama are all trained on largely the same public internet data. When everyone trains on the same information, models inevitably converge. The real moat isn't the model itself. It's the proprietary data that sits behind it. |
Companies that can train on exclusive datasets gain a huge advantage that competitors can't replicate. But the loop only works if you have the right people feeding it. Lawyers. Engineers. Doctors. PhDs and master's graduates, leaders from every discipline. People who actually do the work, who see exactly where models break down in production, who have the judgment to diagnose why, and who can feed that signal back into training.
Anyway, thanks for your service, Sidney. You're not even a year old and already the backbone of an AI analogy in a tech newsletter. You are set for great things. Now, let's talk about what training actually looks like in practice.
How to train a model
So what does it actually look like to train a model? Not in the abstract TED-talk, ‘we use reinforcement learning’ sense. What does a human being do all day?
At its core, the mechanics are simple. The model generates an output. A human evaluates it. The model learns. Repeat this a few million times, and you've got yourself a frontier AI. The thing is, "a human evaluates it" is doing an absurd amount of heavy lifting in that sentence. Because which human makes all the difference. Let’s dive into a mock example of what training looks like in the real world.
1/ A corporate attorney reviews an NDA, and the model says it is clean. It's anything but. There's a non-compete clause buried in paragraph 12 that's unenforceable in California but fully binding in Texas. The model doesn't understand jurisdiction-specific enforceability. It's never litigated anything. Why? Simple. Because it’s not a lawyer.
2/ A financial analyst estimates cost of capital in an emerging market. Two models answer. Both walk through debt ratings, sovereign spreads, WACC. One confuses book values with market values of equity. The mistake cascades through every number. A generalist nods along. An analyst who's priced deals in LATAM catches it right away.
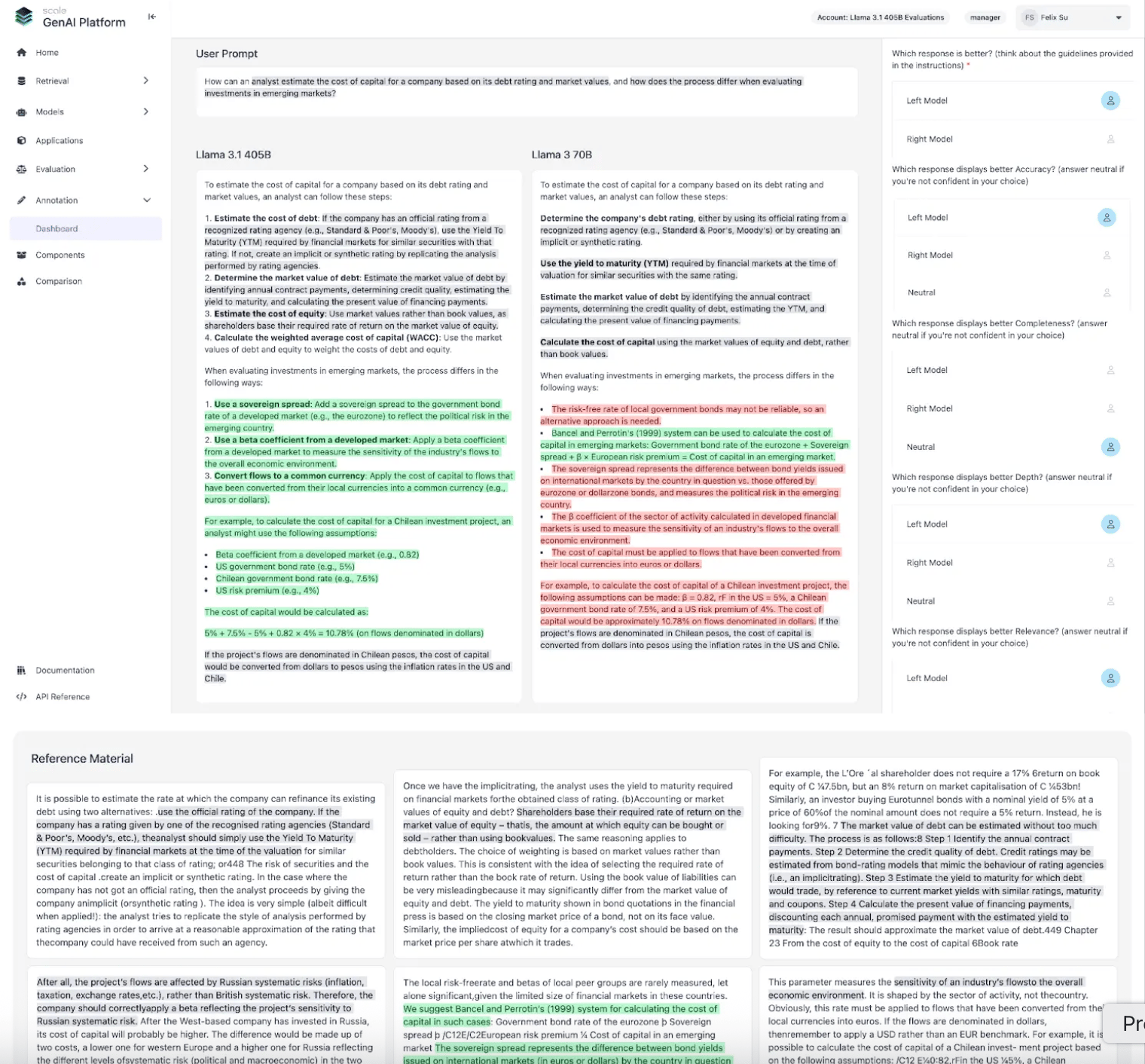
Source: Scale AI.
3/ A mathematician reviews a proof; step by step, it looks airtight. Except that the model has confidently asserted that 3,821 is divisible by 53 and 72. It's not. 3,821 is prime. Duh! One actual mathematician described the phenomenon of AI as ‘very confident nonsense,’ you know the type.
4/ A researcher checks an AI-generated proposal. The citations look legitimate—correct journal names, plausible author names, realistic publication dates—except 69 out of 178 references don't have valid DOIs. Twenty-eight of them don't exist at all. The model invented papers. Confidently.
5/ A linguist evaluates a marketing campaign translated from English to Japanese. The grammar is perfect, but the humor has become humorless, the idioms are literal, and the emotional tone reads like a legal disclaimer. Studies show that literal AI translation can lose up to 47% of contextual meaning and more than half of emotional nuance. The words are right. The meaning is wrong.
A handful of other examples can be found below.
Domain | The task | Where the model fails | Who catches it |
|---|---|---|---|
Radiology | AI reads a chest X-ray and flags a fracture | It's actually an artifact from a venous catheter; the AI can't differentiate between hardware shadow and bone break | A radiologist who's read 50,000 X-rays |
Code | AI generates a function that passes all unit tests | It has a concurrency bug that only surfaced under production load when two threads hit the same resource | A senior backend engineer who's debugged production at scale |
Engineering | AI generates a load-bearing calculation for a steel beam connection | The math is correct for static loads, but hasn't accounted for cyclic fatigue in a seismic zone | A structural engineer who understands failure modes |
Two or three years ago, AI training really was the domain of basic crowd-sourced data labeling. Thousands of gig workers clicking ‘thumbs up’ or ‘thumbs down’ for a few dollars an hour. This still exists, and no shade to all those out there triple-checking that an orange is orange and a dog is a four-legged mammal, but the future has arrived, and it’s owned by the intellects.
The cat is out of the bag
Now that you have lived through the Idiot’s Guide to Training an LLM, I’d like to talk about the industry at large, and how it is an absolutely cashflow volcano hiding in plain sight. Recently, by chance, I stumbled upon Lenny’s tweet citing, “New fastest-growing company in history just dropped.” Obviously, when Lenny says something so outrageous, you take notice.
The company in question was Mercor, which began selling nearshore devs and later pivoted to post-training AI. The claim was that Mercor had grown its recurring revenue from $1M to $500M in 17 months. True breakneck speed, and such a pace that led to Benchmark’s Mitch Lasky bestowing them the title of “fastest growing company in history.” Mercor was founded by three young whippersnappers, Brendan Foody, Adarsh Hiremath, and Surya Midha, who began selling talent but soon, after going through the Thiel Fellowship, smartly pivoted to training AI. |  Foody’s LinkedIn. |
They have since raised $100M at a $2B valuation in February 2025, followed eight months later by a $10B valuation and a $350M Series C. They now have 30,000+ experts on their platform earning an average of $85 an hour.
What I found strange was that Foody seemed to be on a tear, running from podcast to podcast, screaming from the rooftops about their new business model. On top of that, only a month earlier, Garrett Lord of Handshake, the LinkedIn for new U.S. grads, was doing the same thing. After his decade-long startup pivoted part of its operations to training, the team accumulated tens of millions of dollars in revenue in a matter of months. I don’t know about you, but I consider this to be firmly letting the cat out of the bag. If I had stumbled upon an industry that was growing this fast and happened to be leading it, you would have to pry that information from my cold, dead hands.
With immediate fallout from Meta’s June 2025 acquisition of Scale AI—OpenAI, and Google both stopped working with Scale after the deal was announced—a vacuum has opened up, allowing upstarts from a number of industries to fill the void. Turing, Andela, and my company, Athyna, have all entered the arena.
The connective tissue between these companies, with very different origins, was one crystal clear insight: the most valuable commodity in AI isn't compute, code, or even data. It's trained humans who can train machines. The training industry hasn't just seen changes over the last 18 months. It’s been fractured, reshuffled, and grown again, to a size and scale much bigger than before.
The talent war nobody's talking about
The question of AI in 2026 is: Where do you find 30,000 PhDs who want to spend their Tuesdays evaluating whether an AI model correctly interpreted a chest X-ray? Every frontier lab (Anthropic, OpenAI, Google DeepMind, Meta, xAI) has an insatiable demand for expert human feedback, at scale. Not click-farm scale. Expert scale.
They need mathematicians verifying proofs, lawyers spotting buried clauses, engineers evaluating code, and 10,000 other use cases across every domain an LLM touches. If your second cousin has a PhD in molecular bio-something-or-other, tell them to call their wife and tell her to ‘break out the red panties, because babay we made it.’

*If you don’t know that last reference, it was a poorly executed, somewhat obscure Conor McGregor reference that only total MMA nerds would know. Also, I do not condone who Conor has become, but I reserve the right to use his best lines from now until forever, because let's be honest, they are pretty great.
The fact of the matter is that the supply side is very thin. There are roughly 4.5 million PhD holders in the United States. A fraction of them are in the fields that matter most for AI training (computer science, mathematics, medicine, law, hard sciences). An even smaller fraction is willing to do contract evaluation work alongside their day jobs or academic positions. The bottleneck isn't money; these roles pay $85 to $125 an hour. The bottleneck is finding, vetting, and deploying the right people at speed. This is where geography is becoming a weapon.
Brazil, known for many cultural exports, including football and açaí, also has one of the largest concentrations of PhD holders in the Western Hemisphere. Argentina, led by the new age Austin Powers with a chainsaw, Javier Milei, produces world-class mathematicians and computer scientists, and always has. Chile, Mexico, and Colombia all sit on deep pools of advanced-degree talent that Silicon Valley has historically overlooked. And the economics are hard to ignore: a PhD researcher in São Paulo or Buenos Aires can be engaged at 40-60% less than their counterpart in San Francisco or London, while still earning a globally competitive wage by local standards.
Deel’s recent Global Hiring Report 2026, actually showed huge growth in openings for AI trainers, growing 283% cross-border last year. It’s one of the fastest-growing roles in tech, and one that is showing over 40% of talent being paid to come from outside the U.S., in countries like India, the Philippines, and Canada.
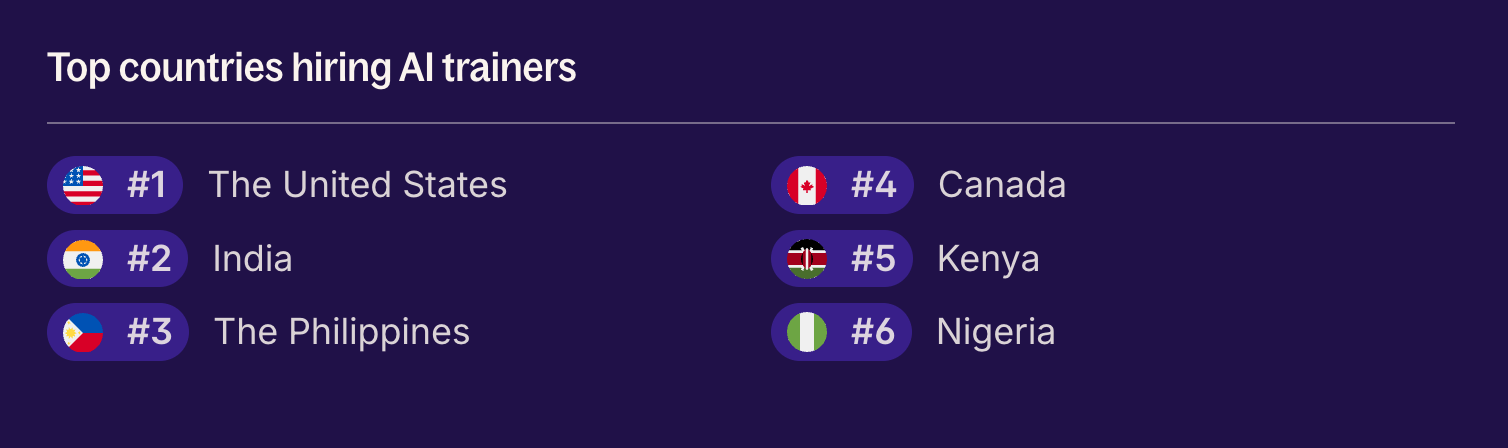 Source: Deel. 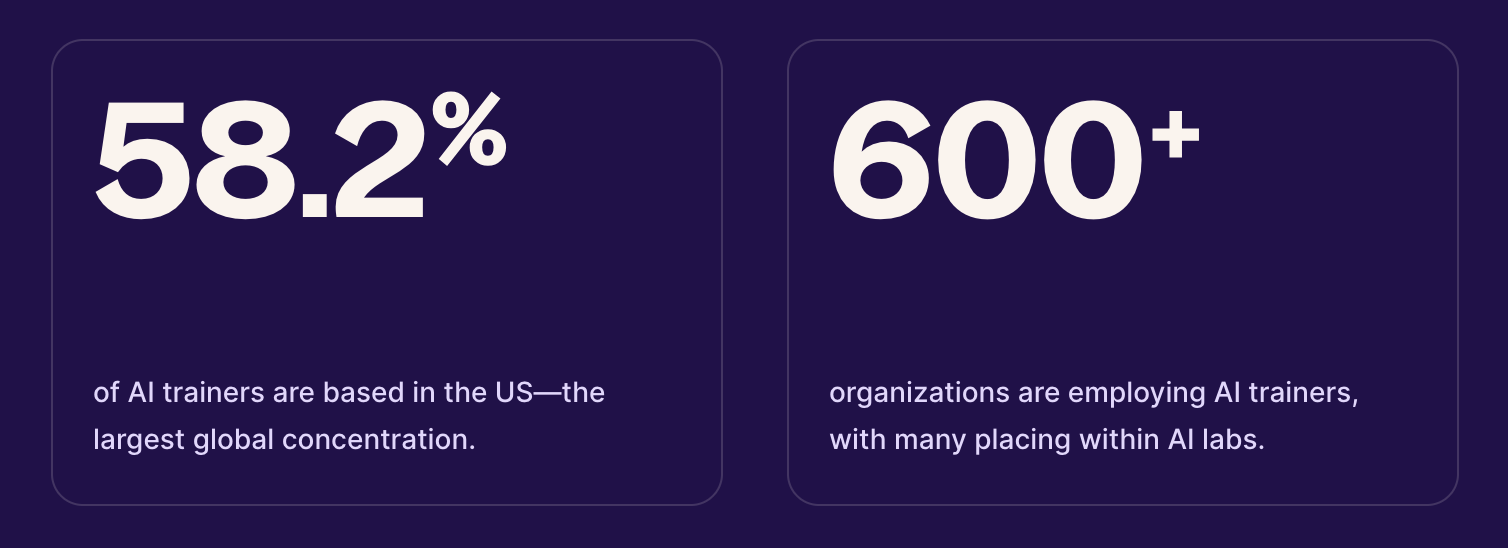 Source: Deel. |  Source: Deel. |
Why we launched Athyna Intelligence
In the spirit of open-sourcing in this newsletter, I like to break the fourth wall from time to time and, in this case, talk about our decision at Athyna to throw ourselves headfirst into the post-training space. The TL;DR is that we've spent the last several years building one of the largest curated talent networks in Latin America. Over 150,000 vetted professionals across engineering, design, marketing, ops, you name it. We've placed talent at more than 1,000 companies, from scrappy seed-stage startups to Fortune 500.
So, you can understand that as soon as my GM and I stumbled upon this opportunity—kudos to Tino for bringing it to me—we started devouring any information we had on it. |  |
This led very swiftly to us coming to the realization that this was: a) within our hitting zone and b) one of the biggest opportunities we could attack at this stage of the business. So, we assembled our version of the Athyna Avengers: myself, Tino, our GM, perennial superstar Josie, now lead of the AI project, and around 10-15 others to tackle things head-on.
What is it? Well, alongside Athyna Talent, our original tech hiring product, we launched Athyna Intelligence, a dedicated vertical within the company focused exclusively on AI training and evaluation. Data generation, annotation, model scoring, classification, reasoning benchmarks, prompt testing; the full stack of what AI labs and application companies need to make their models better. The difference is who is doing the work. Our network includes researchers and advanced graduates with backgrounds in computer science, mathematics, engineering, and NLP. PhDs from some of the best universities in Brazil, Argentina, Chile, and Mexico.
The crazy thing is that we started getting interest from the biggest names in tech in the first month after launch. I am not sure if I am allowed to comment on these conversations, but let’s just say we are currently recruiting for and in conversations with the two biggest ride-hailing apps in the world, a certain search behemoth, a tool to replace Photoshop, and loads more.

With our existing Talent product, we are successful in any meaningful sense of the word: profitable, growing quite nicely, strong culture. But even so, we don’t get inbound and easy-to-open doors from the biggest of Big Tech. I put this down to two things.
Firstly, the talent depth is unmatched. We've spent years building a curated network of researchers, engineers, and advanced-degree holders across Latin America — people who are genuinely world-class at what they do. Time zones are aligned with North America. Culturally aligned with Western business norms. And critically, fast. The fact that the economics also happen to work in the buyer's favor is a bonus, not the pitch. The second is that there is an insatiable demand for this product. In the past, you'd often hear about the war for talent. Today, it is a war for training.
Pssst…also
We’re looking to connect with the heavy hitters in the space, and we’re willing to pay in equity to make it happen. If you can bridge the gap between us and our Dream 100 list—think the big players at OpenAI or Midjourney—we’re offering $25k in equity per successful intro.
The rewards don’t stop there: we’re adding a $50k equity kicker for every client that signs on to our Intelligence product through your referrals. If your Rolodex is full of AI experts and founders, hit me up here. Let's build something big together. |  |
Looking ahead
This industry is going to get much bigger before it gets smaller. Every new model, every new capability, every new vertical application requires more training data, more expert feedback, more human-in-the-loop evaluation. And as models get more capable, the bar for what constitutes 'good' training data goes up.

The companies that win won't be the ones solving the compute problem; they'll be the ones solving the talent problem. Who has access to the deepest pool of domain experts, and who can deploy them fastest? Some smart people think AI will eventually train itself, and maybe they're right. But until then, this gold rush will continue. Only this time, the picks and shovels are people.
Extra reading / learning
What is Vibe Marketing? The Complete Guide - October, 2025
If You Ain’t AI First, You’re Last - November, 2025
Battle Royale: ChatGPT vs Claude - February, 2025
And that's it! You can follow me on Twitter and LinkedIn, and also don’t forget to check out Athyna while you’re at it.
BRAIN FOOD 🧠

TOOLS WE RECOMMEND 🛠️
Every week, we highlight tools we like and those we actually use inside our business and give them an honest review. Today, we are highlighting Vanta*—the security and compliance platform companies rely on to stay audit-ready without losing their sanity.
 |
See the full set of tools we use inside of Athyna & Open Source CEO here.
HOW I CAN HELP 🥳
P.S. Want to work together?
Hiring global talent: If you’re hiring tech, business or ops talent and want to do it 80% less, check out my startup, Athyna. 🌏
See my tech stack: Find our suite of tools & resources for both this newsletter and Athyna here. 🧰
Reach an audience of tech leaders: Advertise with us if you want to get in front of founders, investors and leaders in tech. 👀
 |
Reply