- Open Source CEO by Bill Kerr
- Posts
- Why AI Is Easy To Demo But Hard To Trust
Why AI Is Easy To Demo But Hard To Trust
An interview with Hamel Husain, Founder at Parlance Labs. ⚙️
Bill Kerr
February 05, 2026

👋 Howdy to the 2,345 new legends who joined this week! You are now part of a 249,957 strong tribe outperforming the competition together.
LATEST POSTS 📚
If you’re new, not yet a subscriber, or just plain missed it, here are some of our recent editions.
🚀 Hyperbound Goes Hyperdrive: A Zero To One. Creating the AI-sales training industry and taking names along the way.
⚡️ Launching Athyna Intelligence. An interview with Bill Kerr, Founder & CEO at Athyna.
😩 Your First Product Will Be A Dumpster Fire. Teething problems of world-leading companies.

PARTNERS 💫
Framer is the design-first, no-code website builder that lets anyone ship a production-ready site in minutes. Whether you're starting with a template or a blank canvas, Framer gives you total creative control with no coding required.
Add animations, localise with one click, and collaborate in real-time with your whole team. You can even A/B test and track clicks with built-in analytics.
AI teams need PhD-level experts for post-training, evaluation, and reasoning data. But the U.S. pipeline can’t keep up.
Meet Athyna Intelligence: a vetted Latin American PhD & Masters network for post-training, evaluation, and red-teaming.
Access vetted PhD experts, deep STEM knowledge, 40-60% savings, and U.S.-aligned collaboration.
Interested in sponsoring these emails? See our partnership options here.

HOUSEKEEPING 📨
The news just broke that Elon is merging xAI into SpaceX, bringing both his AI and space ambitions under one roof. I guess it’s just me, but this ruins the SpaceX story for me. As someone who held Elon as my hero of all heroes for most of my life, it saddens me to see his premier asset dirtied by the brand of X. It immediately lessens the prestige of SpaceX.
Now, who cares what I think, right?! Yes, of course, I get that. It’s easy to throw shade at the greatest entrepreneur of our generation, especially from the cheap seats. But I’ve always had the ability to separate Elon the entrepreneur—SpaceX, Tesla, Neuralink, Boring—from Elon the shiteating Twitter troll, poisoning the world’s public discourse. Now, these worlds are colliding. And it leaves a really bad taste in my mouth.

INTERVIEW 🎙️
Hamel Husain, Founder at Parlance Labs
Hamel Husain is an independent machine learning engineer and educator who helps teams build reliable, production-grade AI products, with a particular focus on evaluation (evals), observability, and debugging workflows for LLM systems. He writes and publishes practical field notes on his blog and newsletter, covering topics like eval design, fine-tuning, and LLM infrastructure, drawing on decades of hands-on experience building and shipping ML systems.
He runs Parlance Labs, where he advises companies that have moved past early prototypes and need repeatable ways to measure, diagnose, and improve real-world AI performance. He is also the co-creator (with Shreya Shankar) of the widely known course ‘AI Evals for Engineers & PMs’, which teaches teams how to build evaluation harnesses that drive iteration beyond ‘vibe checks’. Earlier in his career, he worked at companies like GitHub and Airbnb, and has written about his experience building evaluation infrastructure that helped LLM products like GitHub Copilot scale.

What problem are you focused on solving today, and why does it matter?
The main problem I’m focused on nowadays is building AI evals, so evaluations for AI products. What that means is helping people figure out and test whether their AI is actually working or not, and having metrics that are repeatable in a systematic way, so they can improve their system beyond vibe checks and guessing.

Can you tell me a bit about Parlance Labs?
Parlance Labs is a small solopreneur business. I started it to help companies on a consulting basis with AI products, especially companies that were stuck building products with large language models. What I quickly realized was that most of the people I worked with had the same problem. They had glued together the basic components of an AI system, like a RAG database and all the UI components, and they were able to get a prototype out. But they were really stuck on the same issue, which was: now that everything is put together, how do I make it actually work, how do I improve it, and how do I debug it and figure out what to work on next without it feeling like I’m just guessing?
I found myself saying the same things over and over again. So one of the things I started to do with my colleague Shreya Shankar was create a course called AI evals for engineers and PMs. We took about two years of continuous work on this topic and distilled it into a course that helps people avoid all the common pitfalls they fall into when trying to evaluate and build AI systems. It also teaches how to do evals efficiently and effectively, so you get a really high ROI. That’s what we teach.
What drove the shift from big tech to open source to working closely with startups?
A little bit of background on me: I’m a machine learning engineer and I’ve been working in the industry for over 25 years. I’ve worked at a lot of tech companies like GitHub, Airbnb, and a bunch of other startups. I’ve also done a lot of open source work, both as a beneficiary of open source and as a contributor, especially in the machine learning infrastructure space. So it was quite natural for me to get involved with open source.
It evolved organically from being a consumer of open source to contributing to it. |  Source: Parlance Labs. |
My open source contributions have died down a lot recently, mainly because the economics of open source have changed quite substantially. In many cases, it’s now a lot easier to build your own tools with AI. That’s not to say open source isn’t valuable, but sometimes, to get something done, it’s easier to build things yourself up to a certain threshold before you need to contribute to an open source project. The ROI threshold is a little different nowadays, and that’s probably why I contribute less. That said, if there’s an open source project I’m using that has a clear shortcoming, I would definitely contribute. I just haven’t had that need so far.
What does your day-to-day work actually look like as a machine learning engineer?
Day to day, I focus a lot on evals and helping people put processes, systems, and tools in place so they can look at their data, debug why their AI is not working, and set up measurements and automated evals to systematically improve their systems. What my day-to-day ends up looking like is spending a lot of time looking at data. I work with companies, look at their data with them, debug their systems myself, and also teach people how to debug their AI systems effectively.
A big part of that is teaching intuition around when you should write an eval, when you shouldn’t write an eval, and how to approach that process. So my day-to-day involves a lot of looking at traces. Traces are basically logs from an AI system, and I spend a lot of time just looking at traces.
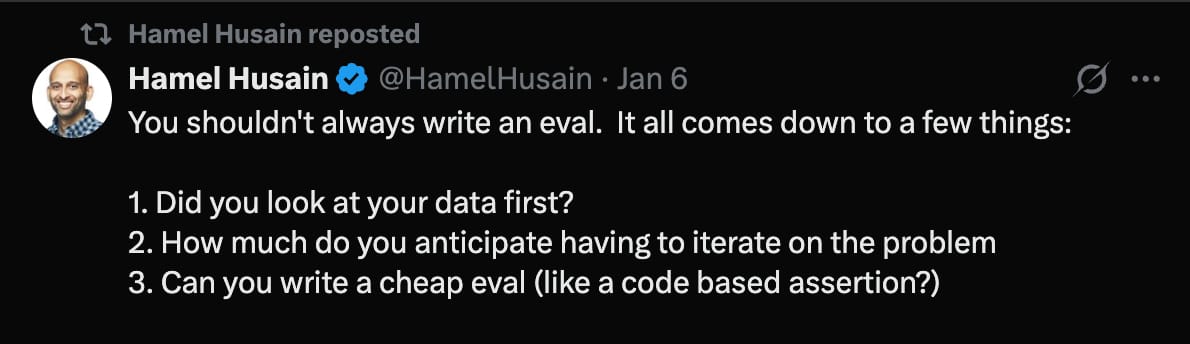
How do you decide which projects or problems are worth your time when a client comes to you?
I try to qualify my clients extensively. What I require is that you’ve already built an AI product and passed the prototype stage, where vibe checks are really good and necessary. You’ve hit a plateau where you don’t exactly know how to improve things, and you’ve hit some kind of wall with AI capability that you’d like to unlock.
It’s also really helpful if people have read some of my writing, taken the course, or have some baseline level of knowledge. If they don’t, I usually point them to free resources or my course first so we can have a shared language before we start. What I try to do is give people as much value as possible and not spend time teaching basics that are easy to learn by reading or watching a video. Once people have covered those bases, then I can work with them.
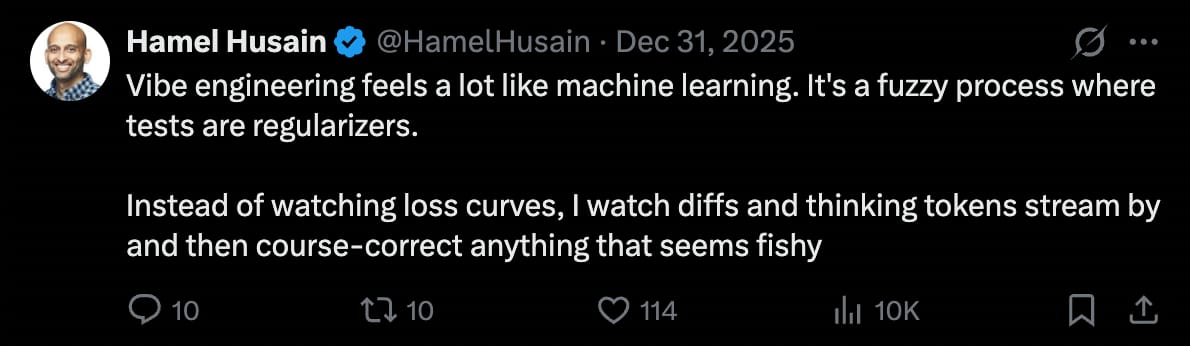
What did working with GitHub Copilot teach you about building LLM products at scale?
GitHub Copilot was a very ambitious project early on. There were only a few people working on it, and honestly, I thought they were kind of crazy at the time. The early idea wasn’t just to do tab completion, but to have an LLM write large chunks of code. At that point, the state of the art didn’t seem anywhere close to being able to do that, and it didn’t feel like the lowest-hanging fruit. Something like semantic code search might have seemed more feasible.
What made it work was evals. The team built a very extensive eval harness based on a curated set of GitHub repositories. They could pull the code, build the environments in a Dockerized setup, and run thousands of existing unit tests at scale. |

The harness would mask certain pieces of code and ask the LLM to complete them, then run the tests to see if the code worked. That alone was a massive effort, because you’re talking about running lots of software and recreating environments at scale.
This was augmented with telemetry, like what code users were accepting or rejecting. All of that data and those evals gave the team a strong signal to iterate against, instead of relying on individual impressions like ‘it kind of works’ or ‘it kind of doesn’t.’ That ability to iterate quickly with real signal at scale was the key to Copilot’s success, and it’s something that’s often missing in modern product development. That’s a big reason why I focus so much on this topic now.
Why do you think machine learning breaks when it’s deployed in real-world environments?
At the core of machine learning, you’re always trying to answer one question: will this system generalize? Generalization is really the operative word here. You try to figure that out by stress-testing your system before deployment, exposing it to diverse data, especially data it hasn’t seen before. That’s one of the main ways we try to approximate how well it might generalize in the real world.
Of course, there are always unknown unknowns. Sometimes users or systems interact with your AI in completely unanticipated ways, and you simply couldn’t have tested for that. That’s one very valid way AI breaks. Another common issue is simply not having good testing practices in place. That’s not the only problem, but it’s a big one.
Machine learning is also a much broader area than just large language models. When you look at ML systems more generally, there’s a lot of technical complexity involved in serving models. There are hardware considerations, software considerations, and challenges around making everything work together in production the same way it did locally or during development. A lot of systems break because of those technical complexities as well.
What’s one belief about ML or AI that you’ve changed your mind about over the years?
One strong belief I have is related to a common myth that’s been circulating recently. In classic machine learning, before large language models, machine learning engineers and data scientists didn’t just train models. They spent a lot of time analyzing where models were breaking, figuring out what needed to be fixed, coming up with metrics aligned with business goals, and deeply understanding the business problem the model was meant to solve. There was a lot of product work involved, using data tools.
A myth that’s emerged with large language models is that you don’t need machine learning engineers or data scientists anymore because you’re not training models yourself. You can just call an API like OpenAI’s and rely on software engineers. While that’s true to some extent, data scientists and machine learning engineers are still incredibly important. Even if they’re not training models, there’s a huge amount of work involved in analyzing what’s working and what isn’t, defining metrics, debugging stochastic systems, and applying the same core skills they’ve always had.


That’s really what evals are. Evals are just data science applied to AI. There’s nothing fundamentally new about it. You have a black box producing outputs, and the question is how you measure and debug those outputs. That has always been the core skill set of data scientists and machine learning engineers. So while some people may think those roles are less relevant now, they very much still are.
What kind of ML or LLM tooling do you wish existed but doesn’t yet?
The tooling itself is actually quite good. We live in a world of abundance when it comes to accessing intelligence through APIs, without having to deal with the complexity of hosting models. That capability is already amazing, and while better models are always nice, I don’t think the biggest gaps are in the model APIs themselves.
What I really wish existed are better products that help people in their daily workflows, especially outside of coding. Coding has been the first frontier for LLM products, and that’s where a lot of the lowest-hanging fruit has been. Most of the innovation so far has been in coding agents and tools that help developers write code.
But there’s a huge opportunity in other areas, like writing tools. Writing is one of the biggest use cases for large language models, yet many writing tools are still very underwhelming. For example, if you open Google Docs, the integration with Gemini is surprisingly weak. If someone leaves a comment saying they don’t like a phrase and want it reworded, why can’t you just click a button and have an LLM apply that change? The model could easily consider the comment and update the text, but that still doesn’t exist. That’s something we already take for granted in coding tools, and it’s surprising it hasn’t made its way into other products yet. There are just so many areas in the product space that feel largely untouched right now.
Outside of work, how do you get the best out of yourself personally and professionally?
One thing I’ll say is that I do work a lot, and I enjoy it. I think it’s very important to sleep properly, exercise, and eat healthy, and I try to do all of those things, even though I’m not perfect at them. Focus is really important, and saying no to a lot of things is important, even though it can be very hard.
As a small business owner and solopreneur, focusing on one thing and trying to do it really well can pay off exponentially, compared to trying to do four things and not achieving much. There are exponential returns to focus, and I think a lot of people don’t fully internalize that because it can feel somewhat extreme.
Is there anything we should have asked you, or anything you’d like to talk about?
That’s a hard question to answer because it really depends on your interests. But one thing I can share more about is the course I teach. It’s called AI evals for engineers and product managers. It’s probably the most popular course of its kind right now. We’ve taught over 3,500 students from the Fortune 500, including more than 50 students from each of the major labs like OpenAI, Meta, and Google.

It’s a very impactful skill set to learn, and it’s highly applicable if you’re building AI products today. I’d really encourage people to check it out. I also write a newsletter at ai.haml.dev, where I share a lot of lessons around evals and related topics. That’s another good place to follow my thinking and work.
Extra reading / learning
Leading Intercom’s AI Transformation - December, 2025
From eBay To Scaling Lannguage - January, 2026
Launching Athyna Intelligence - January, 2026
And that’s it! You can follow Hamel on LinkedIn and Twitter to keep up with him, and check out Parlance Labs on their website to see what they’re building.
BRAIN FOOD 🧠


TOOLS WE RECOMMEND 🛠️
Every week, we highlight tools we like and those we actually use inside our business and give them an honest review. Today, we are highlighting Thesys*—a Generative UI company that helps anyone build AI apps and agents that respond with interactive UI like charts, forms, cards, tables, and more, instead of walls of text.
 |
See the full set of tools we use inside of Athyna & Open Source CEO here.
HOW I CAN HELP 🥳
P.S. Want to work together?
Hiring global talent: If you’re hiring tech, business or ops talent and want to do it 80% less, check out my startup, Athyna. 🌏
See my tech stack: Find our suite of tools & resources for both this newsletter and Athyna here. 🧰
Reach an audience of tech leaders: Advertise with us if you want to get in front of founders, investors and leaders in tech. 👀
 |
Reply